Expressvpn Glossary
Data preprocessing

What is data preprocessing?
Data preprocessing is the method of preparing raw data so it can be accurately analyzed or used in machine learning (ML) models. Real-world data often contains errors, missing values, inconsistencies, or noise. Preprocessing cleans and organizes the data into a structured, reliable format.
Data preprocessing is part of a larger process known as data preparation. It’s also used in traditional data mining workflows, where clean, consistent data is essential for discovering patterns at scale.
Why is data preprocessing important?
- Improves data integrity: Helps snsure each record is complete, consistent, and usable, preventing misleading results and unreliable analysis.
- Creates uniform structure: Standardizes data from various sources and systems to allow for seamless integration.
- Strengthens data mining results: Supplies clean, consistent input, so algorithms can reliably uncover true patterns, clusters, and associations.
- Enhances performance for ML and AI: Enables models to train faster, achieve higher accuracy, and avoid learning biases or noise-induced errors.
- Supports large-scale data processing: Reduces noise in large datasets, making massive or heterogeneous datasets easier to handle.
Key steps in data preprocessing
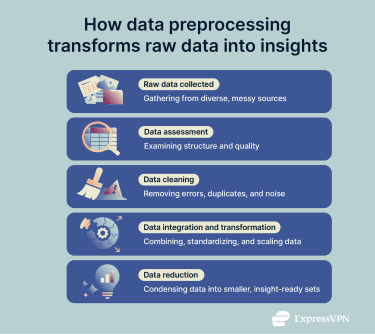
- Raw data collection: Gathers data in its original form from one or more sources, such as user activity logs, sensors, surveys, or transaction records. At this stage, the data is unprocessed and often incomplete or inconsistent.
- Data assessment: Examines the raw dataset to understand its structure and identify problems such as missing values, outliers, duplicates, and inconsistent formats.
- Data cleaning: Resolves the issues found during data assessment by imputing or removing missing values, deleting duplicate records, correcting errors, handling outliers, and standardising formats (dates, currency, or units).
- Data integration: Combines data from multiple sources into a single coherent dataset, resolving mismatches and conflicts.
- Data transformation: Adjusts data to meet analysis requirements or ML tools. This can include scaling numbers to similar ranges, converting text categories into numerical values, or changing how information is represented to make patterns easier to identify. For example, if an image-recognition model doesn’t rely on color, it can convert images to grayscale, which reduces the workload and speeds up training and analysis.
- Data reduction: Makes the dataset smaller so the process is more efficient, while keeping the important information intact. This means only keeping useful information or working with a smaller sample when the full set is too large.
Techniques and tools
Common preprocessing techniques
- Handling missing values: Real-world data often has blank or incomplete entries. This technique fills those gaps or removes the incomplete records so the dataset stays reliable.
- Outlier detection and treatment: Some values sit far outside the normal range and can distort results. Outlier treatment spots these unusual points and corrects or removes them when needed.
- Normalization and scaling: Numbers often appear in very different ranges. Scaling puts them on similar levels, so each value contributes fairly to the analysis.
- Encoding categorical variables: Many tools work only with numbers. Encoding turns text labels, such as categories or groups, into numeric values that systems can understand.
- Feature creation and extraction: New, helpful details can be built from the existing data. These added features highlight patterns that may not appear in the raw dataset.
Popular tools and platforms
- Python libraries: NumPy, pandas, scikit-learn, and libraries such as PyTorch’s torchvision.transforms form a common toolkit for preparing data. They support tasks like cleaning datasets, scaling values, and applying transformations for image and video data.
- R ecosystem: Packages like tidyverse, recipes, and caret offer strong tools for statistical analysis and data preparation.
- Apache Spark: PySpark and Spark MLlib handle very large datasets by spreading work across many machines.
- KNIME: A visual platform that uses drag-and-drop components to prepare data, helpful for teams that prefer to work without code.
- RapidMiner: A commercial platform that provides guided workflows and automation for data preparation, aimed at enterprise use.
- Cloud services: AWS Glue, Google Dataflow, Databricks, and Azure Data Factory offer managed systems that clean and process data at scale.
- Text embedding models: Models such as OpenAI text embedding models or GloVe convert text into numerical representations that capture semantic meaning. These are increasingly used to prepare unstructured text for analysis or as inputs to other ML systems.
Security and privacy considerations
When preprocessing starts, raw data often holds personal details (names, addresses, health info) in plain sight. Many data-processing platforms include features for masking, anonymizing, or pseudonymizing personal information.
When configured appropriately, Python libraries (such as pandas), cloud platforms (such as AWS Glue or Google Dataflow), and workflow tools (such as KNIME or RapidMiner) can scan datasets, detect common identifiers, and help replace them with generated codes.
Further reading
- What is data encryption?
- Data harvesting: What it is and how to stay protected
- What is data privacy and why it matters: A complete guide
